Ulysses’ Specs¶
Before we delve into the job script mystic magic, we have to take a look at the specs of our cluster, Ulysses. Knowing the specs of the cluster is important, as it allows you to carefully balance your computation and to choose the right partition (or “queue”) for the calculation you have to perform.
Specs Sheet¶
Ulysses was originally inaugurated on September 24, 2014; it was originally based on a resource manager called TORQUE (Terascale Open-source Resource and QUEue Manager), a (not anymore) open-source resource manager derived from PBS (Portable Batch System), developed for NASA at the beginning of the 90s.
Ulysses has then been extended and a new infrastructure was made available during late 2019. This new infrastructure consists of additional nodes, an upgraded software stack and a new job scheduler, SLURM (Simple Linux Utility for Resource Management). After the upgrade the old nodes are used in partitions regular1, long1, wide1 and gpu1, while the new nodes are available as regular2, long2, wide2 and gpu2.
But let’s take a closer look at the ID card of Ulysses.
Warning
These info are given as they are, and they are the result of re-elaboration of public documentation [1] [2] on the cluster plus some small info I’ve gathered on the nodes. As this info is basically scattered around in a public form, I guess it’s not classified info; if it is, however, please let me know. There is not, unfortunately, an official spec sheet of the cluster; if you have corrections or more info, please let me know.
- Name: ulysses2
- Operating System: SISSA Linux 7 (CentOS/RHEL 7.7.1908)
- Scheduler: SLURM 19.05.2
- Nodes:
- 2 x Login Nodes (
frontend1.hpc.sissa.it,frontend2.hpc.sissa.it) configured as:- Model: IBM System x3650 M4
- CPU: 2 x Intel(R) Xeon(R) E5-2640 @ 2.50GHz
- Each of the 2 CPUs has 6C/12T, but Hyper-Threading is disabled on the login nodes; so each login node has a total of 12C/12T.
- RAM: 64 GiB
- Disk: ???
- 224 x Compute Nodes v1 configured as:
- Model: IBM System x(R) iDataPlex(R) dx360 M4 Server
- CPU: 2 x Intel(R) Xeon(R) E5-2680 v2 @ 2.80GHz
- Each of the 2 CPUs has 10C/20T. Hyper-Threading is enabled, so each node as a total of 20C/40T.
- RAM:
- 184 nodes with 40 GiB (2 GiB / core)
- 24 nodes with 160 GiB (8 GiB / core)
- 8 nodes with 320 GiB (16 GiB / core)
- 8 nodes with 64 GiB (3.2GiB / core, GPU nodes only)
- GPU:
- 8 nodes, each with 2 x NVIDIA Tesla K20m (each card has 5 GB GDDR5 memory).
- Disk: ???
- 88 x Compute Nodes v2 configured as:
- Model: 77 x HPE ProLiant XL170r Gen9 (for CPU nodes) + 11 x HPE ProLiant XL170r Gen9 (for GPU nodes)
- CPU: 2 x Intel(R) Xeon(R) E5-2683 v4 @ 2.10GHz
- Each of the 2 CPUs has 16C/32T. Hyper-Threading is enabled, so each node as a total of 32C/64T.
- RAM: 64 GiB (2 GiB / core)
- GPU:
- 11 nodes, each with 2 x NVIDIA Tesla P100 PCIe 16 GB (each card has 16 GB HBM2 memory).
- Disk: ???
- 2 x Login Nodes (
- Storage:
- Filesystem: Lustre 2.12.3
/home:- Total: 75.6 TiB (2 x OST with 37.8 TiB each)
- User quota: 198 GiB (hard limit: 200 GiB)
/scratch:- Total: 533.2 TiB (2 x OST with 266.6 TiB each)
- User quota: 4950 GiB (hard limit: 5000 GiB)
Partitions¶
The partitions (queues) are then organized as follows; note that you can get detailed information about a partition via the command scontrol show Partition=<name>.
| Partition | Max
Nodes
|
Max Time
(HH:MM:SS)
|
Max Memory
per Node (MB)
|
Max Threads
per Node
|
Max GPUs
per Node
|
|---|---|---|---|---|---|
| regular1 | 16 | 12:00:00 | 40000 160000 320000(*) |
40 | - |
| regular2 | 63500 | 64 | |||
| long1 | 8 | 48:00:00 | 40000 160000 320000 |
40 | - |
| long2 | 63500 | 64 | |||
| wide1 | 32 | 08:00:00 | 40000 160000(**) 320000(*) |
40 | - |
| wide2 | 63500 | 64 | |||
| gpu1 | 4 | 12:00:00 | 63500 | 40 | 2 |
| gpu2 | 64 |
Note
Clarification on max memory: on the the regular1, long1 and wide1 queues you can normally ask for 40000 MB max memory. However, there are also additional nodes with bigger memory. As as you can see in the Specs Sheet, though, there are not enough “big memory” nodes for all the possible configurations, as there are only 24 nodes with 160000 MB max memory and only 8 nodes with 320000 MB max memory. This means you have to be careful with big memory nodes if you queue jobs in regular1 or wide1. For example, it makes little sense to queue a job requiring all the 8 nodes with 320000 MB max memory in the wide queue, which in principle is useful only for a number of nodes greater than 16. Since there are only 8 nodes with 320000 MB max memory, it would make more sense to take advantage of the increased max time in the long1 queue and queue it there.
Note
Clarification on threads: since Hyper-Threading is enabled on all nodes, there are 2 threads per physical core. However, in SLURM’s job script language, every thread is a CPU; this means that if you ask for “40 CPUs” in regular1 you are actually asking 40 threads, which is 20 physical cores. For a clarification on the definition on socket, core and thread take a look at the picture below.
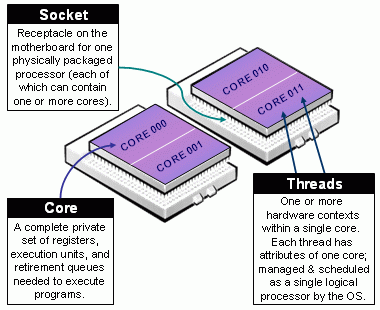
Definitions of Socket, Core, & Thread. From SLURM’s documentation.